В последние годы, по мере того, как системы глубокого обучения становятся все более распространенными, ученые продемонстрировали, как состязательные образцы могут повлиять на что угодно — от простого классификатора изображений до систем диагностики рака — и даже создать угрожающую жизни ситуацию.
Несмотря на всю их опасность, впрочем, состязательные примеры изучены плохо. И ученые обеспокоились: можно ли решить эту проблему?
В течение нескольких лет ученые наблюдали это явление, особенно в системах компьютерного зрения, не зная толком, как избавиться от таких уязвимостей.
Фактически, работа, представленная на прошлой неделе на крупной конференции, посвященной исследованиям искусственного интеллекта — ICLR — ставит под вопрос неизбежность состязательных атак.
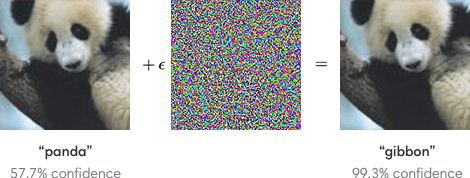
Может показаться, что вне зависимости от того, сколько изображений панд вы скормите классификатору изображений, всегда будет своего рода возмущение, с помощью которого вы сломаете систему.
Но новая работа MIT демонстрирует, что мы неправильно размышляли о состязательных атаках.
Вместо того, чтобы придумывать способы собирать больше качественных данных, которыми кормится система, нам нужно фундаментально пересмотреть наш подход к ее обучению.
Работа демонстрирует это выявлением довольно интересного свойства состязательных примеров, которые помогают нам понять, в чем причина их эффективности.
В чем трюк: случайный, казалось бы, шум или наклейки, которые сбивают с толку нейросеть, на самом деле задействуют очень точечные, едва заметные паттерны, которые система визуализации обучилась сильно ассоциировать с конкретными объектами.
Другими словами, машина не дает сбой при виде гиббона там, где мы видим панду.
На самом деле, она видит закономерное расположение пикселей, незаметное человеку, которое намного чаще появлялось на снимках с гиббонами, нежели на снимках с пандами во время обучения.
Ученые продемонстрировали это экспериментом: они создали набор данных с изображениями собак, которые все были изменены таким образом, что стандартный классификатор изображений ошибочно идентифицировал их как кошек.
Затем они пометили эти изображения «котами» и использовали их для обучения новой нейронной сети с нуля.
После обучения они показали нейросети реальные изображения кошек, и она правильно идентифицировала их всех как кошек.
Исследователи предположили, что в каждом наборе данных есть два типа корреляций: шаблоны, которые на самом деле коррелируют со смыслом данных, вроде усов на снимках с кошками или окраски меха на снимках с пандами, и шаблоны, которые существуют в обучающих данных, но не распространяются на другие контексты.
Эти последние «вводящие в заблуждение» корреляции, назовем их так, как раз и используются в состязательных атаках. Распознающая система, обученная распознавать «вводящие в заблуждение» шаблоны, находит их и полагает, что видит обезьяну.
Это говорит нам, что если мы хотим устранить риск состязательной атаки, нам необходимо изменить способ обучения наших моделей.
В настоящее время мы позволяем нейронной сети выбирать те корреляции, которые она хочет использовать для идентификации объектов на изображении.
Как результат, мы не можем контролировать корреляции, которые она находит, вне зависимости от того, реальные они или вводящие в заблуждение.
Если же, вместо этого, мы бы обучили свои модели помнить только реальные шаблоны — которые завязаны на смысловых пикселях — в теории было бы возможно производить системы глубокого обучения, которые нельзя было бы сбить с толку.
Когда ученые проверили эту идею, используя только реальные корреляции для обучения своей модели, они фактически уменьшили ее уязвимость: она поддалась манипуляции лишь в 50% случаев, в то время как модель, обученная на реальных и ложных корреляциях, поддавалась манипуляции в 95% случаев.
Если подвести короткий итог, от состязательных атак можно защититься. Но нам нужно больше исследований, чтобы устранить их полностью.
Подписывайтесь на наш Telegram канал
Источник: Новости высоких технологий
 Самые актуальные новости - в
Самые актуальные новости - в